The search mechanism of Solr is a powerful and complex tool and it can take some time to get it configured in such a way that users are able to easily find the files that they are after.
In this article we will highlight some of the main aspects to take note of and provide examples and links for further reading.
Tokens
As explained in Understanding the Solr Search functionality in Enterprise Server, Solr handles data by using 'tokens'.
|
Example: The following sentence: "Please, email john.doe@foo.com by 03-09, re: m37-xq." is split into the following tokens: "Please", "email", "john.doe@foo.com", "by", "03-09", "re", "m37-xq" |
The default token length varies between 4 and 15 characters.
Also, Solr by default removes characters such as underscores or dashes from the words that are indexed.
Example: "wi-fi" is indexed as "wi" and "fi".
From this, we can conclude that:
- The more tokens exist, the more search results can be returned (potentially too many to be practical).
-
Terms shorter than 4 characters will be ignored. For terms that are longer than 15 characters, only the first 15 characters are included.
- When a user enters a search phrase that contains underscores or dashes, no results are displayed.
To resolve these issues, we can:
Do this by disabling (commenting-out) the WordDelimiterFilterFactory class in the schema.xml.
Step 1. Open the file <Solr installation directory>/schema.xml.
Step 2. Disable (comment-out) the WordDelimiterFilterFactory class.
<fieldType name="textNGram" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<!--
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="1" splitOnCaseChange="0" splitOnNumerics="0"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
<!--
<filter class="solr.NGramFilterFactory" minGramSize="4" maxGramSize="15"/>
-->
<filter class="solr.NGramFilterFactory" minGramSize="4" maxGramSize="25"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
<!--
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="0" splitOnNumerics="0"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>Step 3. Save and close the file.
Step 4. Re-start Tomcat.
Step 5. Re-index Solr from the Search Server page in Enterprise Server.
Do this by adjusting the 'MinGramSize' and 'MaxGramSize' options in both the schema.xml file and the config_solr.php file. You can either adjust the values to your needs or disable the option altogether.
Step 1. Open the file <Solr installation directory>/schema.xml.
Step 2. Locate any reference to 'MinGramSize=4' and 'MaxGramSize=15' and adjust the value or comment-out the option to disable it.
<filter class="solr.NGramFilterFactory" minGramSize="4" maxGramSize="15"/>
Step 3. Save and close the file.
Step 4. Open the config_solr.php file.
- <Enterprise installation directory>/config/
Step 5. Locate any reference to 'MinGramSize=4' and 'MaxGramSize=15' and adjust the value or comment-out the option to disable it.
//Defines the range used for NGRAM size
define ('SOLR_NGRAM_SIZE', serialize(array(
4, // MinGramSize
// 15, // MaxGramSize
25, // MaxGramSize
))); Step 6. Save and close the file.
Step 7. Re-start Tomcat.
Step 8. Re-start Solr.
Step 9. Re-index Solr from the Search Server page in Enterprise Server.
Step 1. Open the file <Solr installation directory>/schema.xml.
Step 2. Look up the fieldType block starting with <fieldType name="textNGram".
This block contains 2 definitions for 'solr.WordDelimiterFilterFactory' (in analyzer type="index" and "query").
Step 3. Have the original token indexed without modifications by setting preserveOriginal="1"
<filter class="solr.WordDelimiterFilterFactory" preserveOriginal="1" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="0" splitOnNumerics="0"/>Step 4. Save and close the file.
Step 5. Restart Tomcat (it might also be needed to restart Apache as well).
The applied schema.xml changes now need to be applied to the database objects.
Step 6. Access the Search Server Maintenance page in Enterprise Server.
Step 6a. Click Integrations in the Maintenance menu or on the Home page.
Step 6b. Click Search Server.
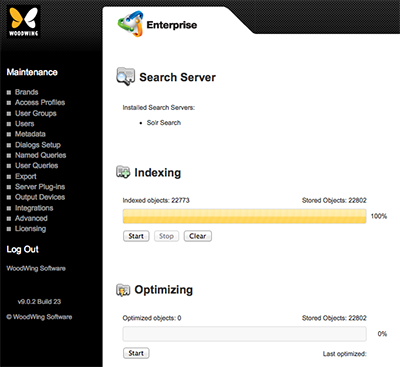
Step 7. In the Indexing section, click Clear, followed by Start.
Additional configuration settings
The examples provided above are just a few of the many possible solutions for getting better search results. Which of these solutions you need for your scenario depends on many factors (such as the type of characters used in file names and the length of file names, both typically controlled by file naming conventions).
Correctly configuring Solr for your environment requires a good understanding of the concepts used by Solr and an awareness of the available settings that can be configured.
We therefore advise to go through the Solr documentation, such as Analyzers, Tokenizers, and Token Filters.
Related Tasks
Enabling sorting on Placed On columns in Enterprise Server 9 with Solr installed
Adding custom Enterprise metadata properties to the Solr search
Changing the time-out period for Solr 4.5
Setting up words to ignore when using Solr in Enterprise Server 9
Setting up synonyms to include when using Solr in Enterprise Server 9
Reference Materials
Comments
0 comments
Please sign in to leave a comment.